
- Document Analyzer
Github clone link
If you encounter a Repository Access Issue after clicking on above link. then fill this form and access will be granted within 1 hour.
Login to your github and go to
https://github.com/cmpt-295-sfu/assignment-1-[GithubName]
DO NOT CLICK ON ABOVE LINK MULTIPLE TIMES.
If you still do not have access contact the head TA on duty (and CC professor). Head TA Name
LINK WILL BE DEACTIVATED 96 hours BEFORE DEADLINE
Meaning create repo at least 4 days before deadline
Academic Integrity
Adhere to the highest levels of academic integrity. Cite any sources that you have referred to. Also, state anyone who you may have discussed your approach with. Use the “Whiteboard approach” discussed in lecture at the beginning of the semester.
You are expected to use the provided data structures and methods only. You are forbidden from using your own methods or data structures that go against the spirit of the assignment and cannot be tested by our tools. E.g., adding your own my_strlen helper method is OK (as long as they do not modify the headers). It is not OK to replace vector_char with your own data structure or methods, knowingly bypassing our methods, or using strtok.
Our internal grading tools will simply mark failed executions as 0. Note that the grade distributed within the assignment scripts is tentative only. If you contravene the rules we cannot guarantee that your code will run against our internal testing.
In many cases below you will see a reference to $REPO. $REPO refers to the folder you have cloned the repo to locally.
# Example $REPO. github username is <student>
git clone git@github.com/CMPT-295-SFU/assignment-1-student
# $REPO is the folder assignment-1-student.
Goals
- Enhance your understanding of pointers in C
- Work with complex pointer-based data structures
- Preparation for working with hardware
Check Yourself
- Have you completed lab 0?
WARNING: WE CANNOT GRADE YOU UNTIL YOU HAVE COMPLETED LAB 0! - Do you know how to access fields in a struct?
- Do you know how to
malloc,reallocandfree? Watch Week 2 video - Do you know how to use
cgdb? - Do you know how to print in hex? (See Week 1)
If you cannot answer these questions, revise lab 1 and read:
- Essential C: Particularly section 3.
- Do you know what in
gcc -I./includewhat does the-Iflag does. Short answer: It adds additional folders for compiler to search for headers. Answer - Do you know what
make -ndoes? It’s a dry run that shows what commands are being run by make during the build process.
Arraylist - Practice
NOT GRADED
Prereq self assesment deadline: Try to complete within 1st three days
Expected Completion Time: 1 hour.- This part tests your understanding of pointers and dynamic memory allocation which should have been covered by the prerequesite courses CMPT125 and CMPT130.
- If you find this part challenging, it is an indication that you need to review the prerequsite courses.
Source
In this module we will implement 3 functions in the file Arraylist/arraylist.c:
void arraylist_add(arraylist *a, void *x)void arraylist_free(arraylist *a)void arraylist_insert(arraylist *a, unsigned int index, void *x)
YOU CANNOT MODIFY ANY OTHER FILES OR FUNCTIONS.
Step 1: Implement the arraylist_add
(arraylist* a, void* x)
The elements of an arraylist are stored consecutively in a dynamically allocated array. This function takes a pointer to an arraylist and a value, and appends that value to the end of the arraylist. It should also increment the length of the arraylist to include the new element.
If this is a conceptual drawing of what the arguments to the function look like at the beginning of a call to arraylist_add:
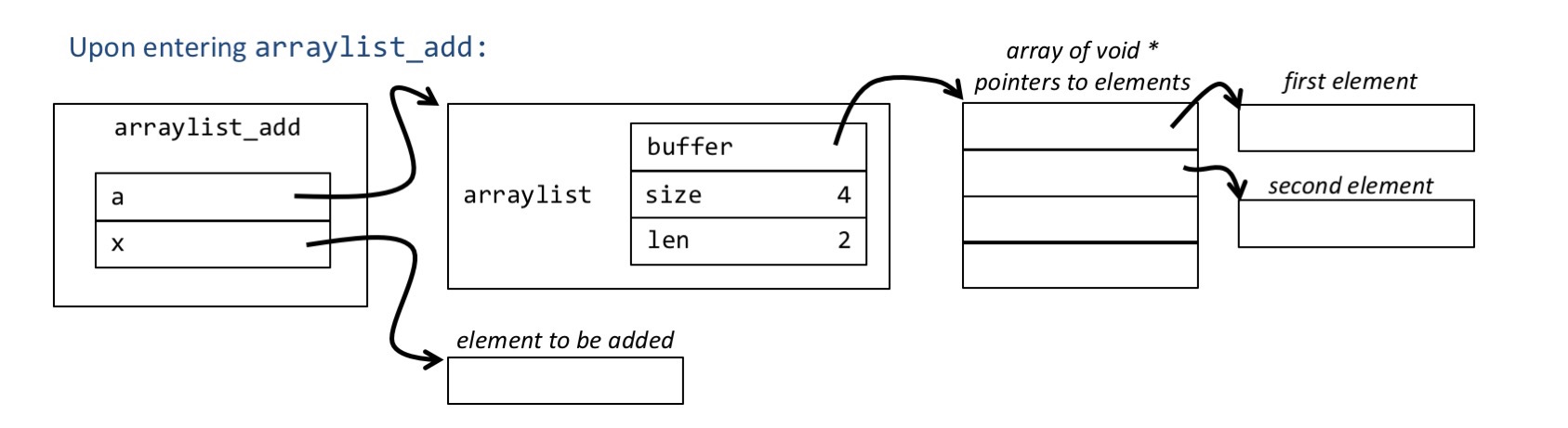
Then this is a conceptual drawing of what the arguments should look like at the end of the function arraylist_add:
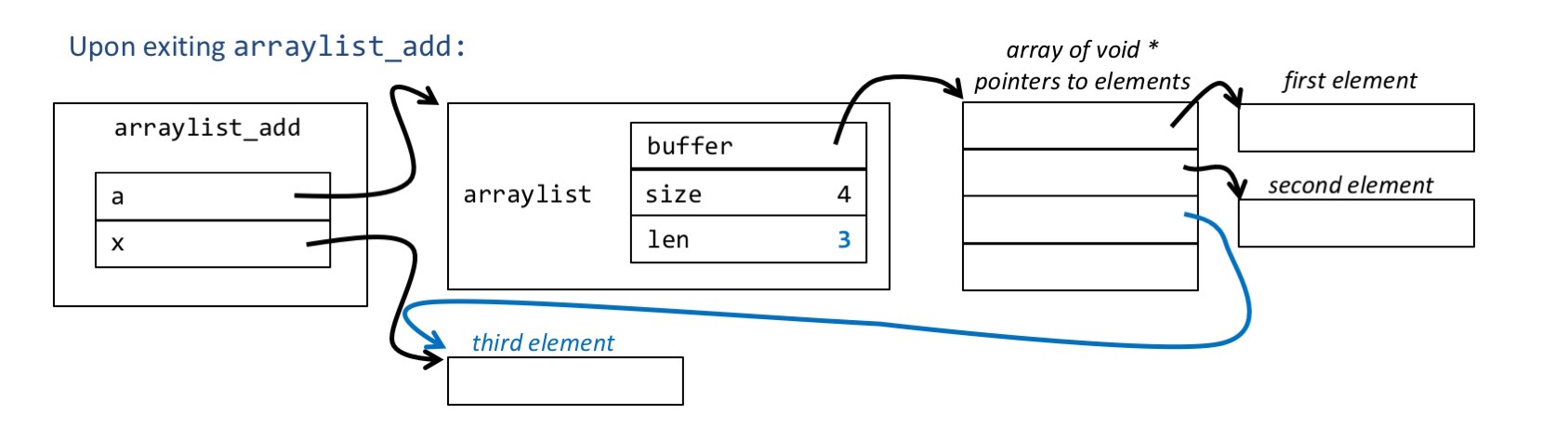 .
.
If the arraylist is currently at capacity when arraylist_add is called, you should create a new dynamic array that is twice the size of the old one and copy over all the current elements in the arraylist. You may find the standard library function realloc useful for doing this.
Step 2: Implement arraylist_insert
(arraylist* a, unsigned int index, void* x)
Hint: Use memmove(). This function should take advantage of your arraylist_add to insert an element at an arbitrary location in your arraylist. You do not have to worry about attempting to insert to locations beyond the end of the arraylist (doing so is undefined behavior).
Step 3: Implement the arraylist_free
(arraylist* a)
The arraylist_free simply has to free all the resources used by an arraylist. Note that the arraylist struct contains a pointer!
Test and Validate
$ cd $REPO
$ cd Arraylist
$ make -n # prints the steps for building the executable
gcc -c -o obj/arraylist.o arraylist.c -ggdb -I./include
gcc -c -o obj/main.o main.c -ggdb -I./include
gcc -o arraylist.bin obj/arraylist.o obj/main.o -ggdb -I./include -lm
$ make # Builds the executable
$ ./arraylist.bin --verbose
# If success
Test Test 0:
Case Add:1-5: Inserts numbers 1 to 5.
main.c:90: Check !strcmp(vec->output, output)... ok
SUCCESS: All conditions have passed.
Test Test 1:
Case Add:1-3,Insert:100:0-3: Inserts numbers 1 to 5. followed up insertion of 100 at positions 0-3.
main.c:127: Check !strcmp(vec->output, output)... ok
SUCCESS: All conditions have passed.
Test Test 2:
Case Add:1-5,Insert:100:0-6,Free: Inserts numbers 1 to 5. followed up insertion of 100 at positions 0-3. Finally free the arraylist.
main.c:60: Check !strcmp(vec->output, output)... ok
SUCCESS: All conditions have passed.
Summary:
Count of all unit tests: 3
Count of run unit tests: 3
Count of failed unit tests: 0
Count of skipped unit tests: 0
# If test case fails, you will see the expected output.
# Test 1 and 2 WILL LEAK MEMORY. TEST 3 should not.
Document Analyzer
This assignment will help you understand
- how to use C pointers and data structures.
- how to allocate and deallocate memory.
- how to write larger C programs.
You will write a C code that takes in an input string and:
- splits it into words.
- creates a dictionary of words (i.e., list of all unique words).
- counts the number of occurrences of words.
Alphanumeric character: An alphanumeric character (includes any of a-z, A-Z, or 0-9). Any character that is not a alphabet or digit should be ignored and is not considered part of the word. Read Hint
Word A word is a sequence of alphanumeric characters separated by non-alphanumeric character.
e.g.,
Input string: Lorem Lorem i dolor sit amet,
Step 1: Words:
# Notice that we ignored the space and punctuations.
Lorem
Lorem
i
dolor
sit
amet
# Step 2: Dictionary of words (only unify)
1. Lorem
2. i
3. dolor
4. sit
5. amet
# Step 3: Word counts
Lorem:2
i:1
dolor:1
sit:1
amet:1
Source files
All command files below here refer to word-count folder
cd $REPO
cd word-count
| Filename | Description |
|---|---|
| dictionary.c | TODO: main(). Implement dictionary |
| tokenize.c | TODO: main(). Implement tokenizer |
| poscount.c | TODO: main(). Implement line count |
| include | header files |
| obj | where compiled .o files are stored |
| txt | Input test files. |
| out | folder for holding output from tests |
| reference | Reference output for each step |
| str_cmp.c | TODO: Implement your own strcmp |
| vector_char.c | A dynamically resizable character array |
| vector_string.c | TODO: A list of words |
| table_string.c | TODO: A table of words |
| unit_test_vector_char.c | A simple program illustrating vector chars |
| unit_test_vector_string.c | A simple program to test your vector string implementation |
Rules
- For this assignment you cannot use any of the following functions:
strcmp|strlen|isalnum|isalpha|isdigit|strdup|strcat|strncpy|strncmp|strtok. You can read about them here. You will have to write your own implementations if/when required. - You can only modify the source code with
TODO:blocks in the code. You can modify or add files prefixed with unit_test. - Attempt steps below in order.
Check Yourself
WARNING: DO NOT PROCEED WITHOUT UNDERSTANDING THE FOLLOWING
- Do you know the difference between char* and char**? See example
- Do you know what the ``\0’` character is ? Null terminated string. Iterating over character array without \0
- Do you know what is the int value representing
'a'and'A'? What is the ascii table? Ascii Table Lecture 1 Slides - In the code below, what is the size (in bytes) of
header_as_typevs.header_as_pointer? what is the size (in bytes) ofentry_t? What is the problem with line 24 (head_p.variable->value = string;)? Run in python tutor here.WARNING: DO NOT PROCEED WITHOUT UNDERSTANDING THIS EXAMPLE AND HOW TO FIX THE UNINITIALIZED POINTER
struct entry_t {
char *value;
char *next;
};
struct header_as_type {
struct entry_t variable;
};
struct header_as_pointer {
struct entry_t* variable;
};
void main() {
struct header_as_type head_t;
struct header_as_pointer head_p;
char string[] = "Hello World";
head_t.variable.value = string;
printf("%p",head_t.variable.value);
// INCORRECT EXECUTION.
// UNCOMMENT Line below if you want correct execution
// head_p.variable = (struct entry_t*)malloc(sizeof(struct entry_t));
head_p.variable->value = string;
printf("%p",head_p.variable->value);
}
Step 0: String comparison
Compare two character arrays. Return 0 if they match, 1 otherwise.
- You can assume that
s1ands2are null terminated strings. WARNING:strings could potentially be of different lengths e.g., “apple” does not match “apple “ (which includes the extra space). Value to be returned will be 1.- You cannot use any of the string helper functions including
strlen,strncmp, andstrcmp. - Read here for C’s own strcmp.
WARNING: Our my_str_cmp is slightly different. When strings mismatch, we simply return 1
SOURCE FILES
If you do not fill any code and simply try running, there will be a segmentation fault and/or compiler errors.
| Filename | Description |
|---|---|
| str_cmp.c | TODO: Implement string compare |
| test_str_cmp.c | YOU CANNOT MODIFY THIS FILE. Tester for str_cmp (will not work with gdb) |
| unit_test_str_cmp.c | TODO: Write your own unit test case for gdbing |
# Build unit test case
gcc -I./include/ unit_test_strcmp.c str_cmp.c -o unit_test_strcmp.bin
Complete testing and grading
make test_strcmp.bin
./test_strcmp.bin --verbose
Test Test:
test_strcmp.c:24: Check result == test_vectors[i].expected... failed
String s1: a
String s2: b
test_strcmp.c:24: Check result == test_vectors[i].expected... failed
String s1: apple
String s2: appl@
test_strcmp.c:24: Check result == test_vectors[i].expected... failed
String s1: apple and oranges
String s2: apple and oranges
test_strcmp.c:24: Check result == test_vectors[i].expected... failed
String s1: 123456
String s2: 123456
test_strcmp.c:24: Check result == test_vectors[i].expected... failed
String s1: 342342;
String s2: afasdfsafd;
FAILED: 5 conditions have failed.
Summary:
Count of all unit tests: 1
Count of run unit tests: 1
Count of failed unit tests: 1
Count of skipped unit tests: 0
You should now see the fruits of your labor! If any of these cases fail, the tester will display the produced and expected values. Use this feedback to check results constructed by your approach.
Step 1: Word Tokenizer
A word tokenizer cuts an input string into individual words. For our purposes, a word is defined as a contiguous sequence of alphabets or numbers (from 'a' to 'z', 'A' to 'Z', and '0' to '9').
Helper Source Files
A useful data structure for tokenizing is a character vector. Since words in the input string can vary in length, a vector is useful as it can dynamically grow. C lacks a dynamic vector and only supports fixed-size arrays. We have provided vector_char, a dynamic character array with helper functions. You do not need to know how vector_char works (however it may help if you do). You do need to know how to use the provided api.
Watch youtube video on vector char
To assist you in implementing the word tokenizer, we have provided the following helper files:
vector_char.c: Implementation of thevector_chardata structure (DO NOT MODIFY)unit_test_vector_char.c: Example usage of thevector_chardata structure
You can compile and run the unit_test_vector_char.c file to see how the vector_char works.
| Filename | Description |
|---|---|
vector_char.c |
Implementation of vector_char. DO NOT MODIFY |
unit_test_vector_char.c |
READ: Illustrates how to use a vector_char |
make unit_test_vector_char.bin
./unit_test_vector_char.bin ∞
Actual:HELLO WORLD
Lower: hello world
Length (without \0 termination character): 11%
If you can answer the following questions, you can proceed.
- What does
vector_char_allocate()allocate?spacefor string ORspacefor pointer to string? - Where does the header reside?
unit_test_vector_char.c line 10: vector_char_t *header? stack or heap? - where is
header->dataallocated? stack or heap?
MODIFY SOURCE FILES
tokenize.c is where main is located. To make it easier, we have already provided the basic code for reading the input file into a null terminated character array called source.
Follow the instructions in tokenize.c.
./tokenize.bin txt/small.txt
# source contains contents of txt/small.txt as character array
| Filename | Description |
|---|---|
tokenize.c |
TODO: Modify listing to iterate over string and tokenize |
refererence/.tokenize |
Reference outputs. Your output should match that |
Test and Validaton
If things work correctly then the output of tokenize.bin should be as shown below.
IMPORTANT: See below for grading
make tokenize.bin
# Test below shows expected output.
./tokenize.bin txt/small.txt
Lorem
Lorem
i
dolor
sit
amet
# Validate
./tokenize.bin txt/small.txt > out/small.txt.tokenize; diff out/small.txt.tokenize reference/small.txt.tokenize
If you use vscode, it has a more powerful and visual diff:
$ code --diff out/small.txt.tokenize reference/small.txt.tokenize
# Source is the array of characters that needs to be tokenized into words
# This is only meant to be a guide and may not be fully accurate or correct
for ch in source[]:
word = new word()
if ch is alphabetical
word.add(ch)
else
if word is not empty:
print word
word = ""
WARNING 1: You cannot use strtok.
WARNING 2: You cannot assume the max word length is known.
WARNING 3: The data ptr may change as you call vector_char_add and other functions
Use vector_char. It is required and there to help you. Further its required in subsequent steps.
Step 2: Dictionary
Now that we know how to tokenize, let’s build a dictionary. A dictionary is a collection of all the unify words. e.g.,
1. Lorem
2. i
3. dolor
4. sit
5. amet
Pseudocode
for each word (w words)
// Each word
lookup word in vector string
if word is present, continue
else
insert at the end of vector string
end
entries = array of all dictionary keys (words) in the vector string
for each entry
print index + ". " + word
end
Check Yourself
- Do you know what a linked list is? Linked list wiki
- Have you completed Part 2? C-Lab-1?
MODIFY SOURCE FILE
To help you with this task we want you to implement a data structure called vector_string, a dynamic linked list in which each entry points to a dictionary word.
| Filename | Description |
|---|---|
include/vector_string.h |
READ Contains the top-level structs describing the vector_string |
vector_string.c |
TODO: Implement the TODO blocks |
refererence/\*.dictionary |
Reference outputs. Your output should match that |
dictionary.c |
TODO: Implement main() |
You are expected to implement the following five functions:
vector_string *vector_string_allocate();Creates a vector string on the heapbool vector_string_find(vector_string *vs, char *key);Searches the vector string pointed to byvsand returnstrueif entry found,falseotherwise.void vector_string_insert(vector_string *vs, char *key);Inserts a string into the vector string at the tail.void vector_string_deallocate(vector_string *vs);Removes all entries and deallocate vector string.void vector_string_print(vector_string *vs);Prints all value in each entry of the vector string, one line at a time.
WARNING: print format has to exactly match for tests to pass
Test and Validation
make dictionary.bin
# Validate
./dictionary.bin txt/small.txt > out/small.txt.dictionary; diff out/small.txt.dictionary reference/small.txt.dictionary
Step 3: Position count
Track each word’s position occurs. Provide a list of all dictionary words in a document along with the exact line number in which they occur. First word in file is at position 0 and so on. The order of position here depends on table_string buckets (DO NOT MODIFY THIS in poscount.c)
$ cat word-count/reference/input.txt.poscount
adipiscing: 6
felis: 24
diam: 39
posuere: 41
Vivamus: 42
Sed: 8 65
eleifend: 11
est: 17
maximus: 23
nunc: 27 34
semper: 52 55
id: 12
at: 14 54
hendrerit: 19
ex: 25
orci: 31
eget: 38 62
justo: 50
cursus: 51
elit: 7
ligula: 10 30
nec: 16
ullamcorper: 22
Integer: 35
tempus: 40
bibendum: 64
metus: 66
dictum: 71
Lorem: 0
amet: 4 33 57 70
consectetur: 5 68
tempor: 36
pharetra: 47
augue: 67
dolor: 2 37
sit: 3 32 56 69
fringilla: 43 60
ante: 49 58 75
mollis: 53
sapien: 61
i: 1
enim: 9
vehicula: 13
congue: 15
Curabitur: 18 59
eros: 20
ut: 28
mauris: 45
a: 46
Donec: 48
vitae: 74
eu: 21
mattis: 26
tincidunt: 29 44
tristique: 63
quis: 72
vulputate: 73
....
....
If you open txt/input.txt in a text editor
and search for ligula, you will see it is the 10th word & 30
while adipiscing occurs only at position 6
Hints
- You can look for special character similar to tokenize to start a new position.
- You will be using a dynamic array to track the set of pos numbers.
- Make sure you free the array in the end. You cannot make any assumptions about the size of the array. Refer slides in Week 2 for:
realloc. (https://www.tutorialspoint.com/c_standard_library/c_function_realloc.htm) - Remember in C you do not know the size of dynamic arrays, hence you have to explicitly track it in a variable.
SOURCE FILES
A key limitation of the vector_string is that it uses a single linked list to keep track of the words in the document. Hence searching through it is expensive. Think of the checking if a word exists? In the worst-case how many entries in the list would we have to check?. To make things faster we will be building a new data structure with new methods: table_string. Figure below illustrates a table_string. Unlike a vector_string, a table_string maintains multiple lists (you can refer to these as buckets). Each word is hashed or mapped to a unify bucket. The function djb2_word_to_bucket(char* word, int buckets):table_string.c takes in a string and returns the bucket corresponding to the word. It returns a value between [0,buckets-1]. The word should be inserted only in that bucket. Each bucket is simply a linked list of entries. This ensures that words are naturally partitioned between buckets. The linked list in each bucket will not be as long and this makes it faster and easier to search for a particular word.
| Filename | Description |
|---|---|
include/table_string.h |
READ Contains the top-level structs describing the table_string |
table_string.c |
TODO: Implement the TODO blocks |
unit_test_table_string.c |
READ. Contains unit test and framework for illustrating how to use table string |
poscount.c |
TODO: main() for tracking which poss a word occurs in |
These are the four functions that you are expected to implement for table_string:
table_string *table_string_allocate();Creates a table string on the heap. The reference outputs were generated assuming atable_stringwith 8 buckets.void table_string_insert_or_add(table_string *vs, char *key, int pos);Inserts the word pointed to bykeyinto the table string at the tail (if it does not exist), otherwise adds new pos entry. Refer tovs_entry_tininclude/vector_string.h. Bothtable_stringandvector_stringuse nearly identical entries (table_stringincludes extra array for tracking the poss in which each word occurs.)void table_string_deallocate(table_string *vs);Removes all entries and deallocate table string
void table_string_print(table_string *vs);Prints all values in each entry of the table string. See above for formatWARNING: print format has to exactly match for tests to pass. See table_string.c
WARNING: It is very important that you insert at the tail in each bucket
If the order of words in the bucket or the bucket in which you insert a word
is wrong then you will not match the reference output
# Make sure you initialize the table_string with 8 buckets in poscount.c
# The reference output was generated assuming 8 buckets
# in the table string.
# If you do not set buckets to 8, then each word will be fine. But the order of the words could be different leading to mismatches against the reference
cd $REPO/word-count
make poscount.bin
# Validate.
./poscount.bin ./txt/small.txt > ./out/small.txt.poscount; diff ./out/small.txt.poscount ./reference/small.txt.poscount
Step 4 Word Pair Search
We are going to build a useful application leveraging existing data structures. Hash-based table strings enable efficient word lookup by partitioning words across buckets. We will implement a consecutive word pair detector. Given two files, find all consecutive word pairs from file 2 that also appear consecutively in file 1, then output each matching pair with its starting position from file 1. The algorithm steps are as follows:
If you open txt/input.txt and txt/small.txt in a text editor
and search for word pairs from small [Lorem i],... , you will find that [sit amet] at position 3, then at 32, and then again at 56 and 69.
WARNING: print format has to exactly match for tests to pass. See reference
We will now proceed to find the occurences of all word pairs from one file in another.
# Make sure you initialize the table_strings with 8 buckets in duplicate.c
# The reference output was generated assuming 8 buckets
# in the table string.
# If you do not set buckets to 8, then each word will be fine. But the order of the words could be different leading to mismatches against the reference
$ cat reference/input.small.mapcount
Lorem i 0
i dolor 1
dolor sit 2
sit amet 3
sit amet 32
sit amet 56
sit amet 69
Example: Word Pair Extraction
Input file (small.txt):
Lorem Lorem i dolor sit amet,
Consecutive word pairs extracted:
Lorem Lorem(positions 0,1)Lorem i(positions 1,2)i dolor(positions 2,3)dolor sit(positions 3,4)sit amet(positions 4,5)
Search process: For each pair, check if both words appear consecutively in the target file (input.txt). For example, if “Lorem” appears at position 0 and “i” appears at position 1 in input.txt, then the pair “Lorem i” is found and we output: Lorem i 0
SOURCE FILES
- Create a table string to track the occurrence of words in each file. You will create one table string for file 1 (let’s call it
table1). - Tokenize the words from file2.
- Iterate over the words keeping track of pairs of words i.e., the cur word and next.
- Get all positions of current word - cur_word_pos
- Get all positons of next word - next_word_pos
- If there exists i \(\in\) cur_word_pos and j \(\in\) next_word_pos. such that j == i + 1 then we found the word pair.
- Display it
table_file1 = table_string_create(file1)
words_file2 = tokenize(file2)
for i in range(len(words_file2) - 1):
cur_word = words_file2[i]
next_word = words_file2[i + 1]
cur_word_pos = table_string_get_positions(table_file1, cur_word)
next_word_pos = table_string_get_positions(table_file1, next_word)
for i in cur_word_pos:
for j in next_word_pos:
if j == i + 1:
print(f"{cur_word} {next_word} {i}"
| Filename | Description |
|---|---|
mapcount.c |
TODO: Implement the mapcount function for searching word pairs from one file in another |
There is only one function that you are expected to implement for common word counts:
Test and Validation
# Make sure you initialize the table_string with 8 buckets in poscount.c
# The reference output was generated assuming 8 buckets
# in the table string.
cd $REPO/word-count
# Even though binary name says mapcount. Note that you
# are expected to implement common word count finding algorithm.
make mapcount.bin
# To test make sure you are in the parent folder
cd $REPO
./word-count/mapcount.bin ./word-count/txt/input.txt ./word-count/txt/small.txt > ./word-count/out/input.small.mapcount
diff ./word-count/out/input.small.mapcount ./word-count/reference/input.small.mapcount
# To match reference output, you have to run from the $REPO folder.
Grading
Congrats! You are now ready to receive your tentative grade.
$ cd $REPO # $REPO refers to the top of your cloned repo.
$ source ./scripts/localci.sh # run from the repo folder
# Check if SUCCESS OR FAILED was dumped by scripts
# There will be a _Grade.json (this is your tentative grade). The file is in json format.
# The mark component in each module indicates your score for that portion.
# LOG.md contains the log of your runs. This will give you more information. See the FAILED header.
# To check if you are using these banned functions.
$ cd $REPO/word-count
$ egrep "strcmp|strlen|isalnum|isalpha|isdigit|strdup|strcat|strncpy|strncmp|strtok" table_string.c vector_string.c dictionary.c tokenize.c poscount.c mapcount.c -n
# You can ignore line. word-count/table_string.c:21: for (i = 0; i < strlen(word); i++). This is code provided by us. You can also ignore any usage in unit_tests. We do not grade unit_tests.
# The above will return any lines where you are using those banned functions.
# Note that if you are writing your own my_strlen and use it anywhere in your code it will match again. You will have to rename it to something like my_str_len
This grade is only tentative. Based on additional test cases in our evaluation, you could score less points. If valgrind reports any memory errors other than leaks e.g., writes to unallocated memory etc then your score will be zeroed out for that portion
| Module | Total |
|---|---|
| arraylist | 5 |
| strcmp | 5 |
| tokenize | 20 (+5 points if no memory leaks) |
| dictionary | 20 (+5 points if no memory leaks) |
| poscount | 20 (+5 points if no memory leaks) |
| mapcount | 40 (+5 points if no memory leaks) |
Memory Management
In this assignment, you are also expected to manage your memory and prevent memory leaks from happening. A good tool for checking whether your program has memory leak is Valgrind. You can learn how to use it here. A short example is below. We will deduct points if you fail to free all memory before the program exits.
$ valgrind --leak-check=yes ./executable
Debugging tips
Valgrindrunmemcheckto find uninitialized memory locations and references
$ valgrind --tool=memcheck ./executable
- Read here to find common errors Slide 29
- Refer here to catch typical memory errors
- If you see garbage characters after your string e.g.,
Lorem^?. Check if you inserted null termination character. - Follow gdb instructions from lab 0
- Are you writing unallocated memory
- Use python tutor to visualize individual functions. Your code has to be < 200 lines of code.
- If your output seems similar to reference but you are still failing, then check for additional spaces or new lines.

- Do not forget to free the line array in table-string at the end.
TA Help
We strictly adhere to a ‘No Print No Help’ policy. Please review the policy on assignment page for more details. To ensure the TA meetings are productive, we recommend bringing the following information:
- The
datapointer andstructpointer ofvector_char. - Each node in the linked list of
vector_string(includinghead,tail, andnext). - The array of buckets and nodes in the linked list of
table_string.
Please ensure that you have thoroughly reviewed your code and attempted to debug the issue before seeking assistance.