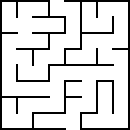
Find any “important” points in the maze and call them nodes; connect nodes with edges when they are connected in the graph:
Now we have a graph that captures everything important about the maze:
And we can ask how about a path from \(a\) to \(k\) in that graph.
… or the shortest path, or the path that visits the most places on its way, or…
We didn't really have to select only “important” points as our vertices.
We could have made every grid location a vertex, and joined them as appropriate.
That would have created a much bigger graph (64 nodes, many with degree 2), but still captured everything about the maze.
Maybe that graph would have been better: getting the shortest path would have been more meaningful.
Example: computer networks.
We can take the computer to be nodes, and connections between then to be edges.
Undirected graph: every networking technology is bidirectional.
Maybe a multigraph if we want to represent that computers might have multiple redundant connections between them.
But usually a simple graph: put an edge if the computer are connected in any way.
Again, we can then ask questions about how to route information between two computers, or how many paths there are between computers, or what connections could fail without losing connectivity, or….
Graph Basics
Two nodes that are connected by an edge are called adjacent.
An edge connects the nodes at either end.
The number of edges at a node is the nodes degree.
Where we need to, we'll write \(\operatorname{deg}(v)\) for the degree of vertex \(v\).
These imply that \(2|E|=\sum_{v\in V} \operatorname{deg}(v)\).
… since each edge has two ends.
Corollary: the number of vertices with odd degree must be even.
In a directed graph,
An edge from \(u\) to \(v\) has \(u\) as its initial vertex and \(v\) as its end vertex.
We have to count degree separately.
The count of edges with \(v\) as the initial vertex is its out degree, \(\operatorname{deg}^{-}(v)\).
The count of edges with \(v\) as the end vertex is its in degree, \(\operatorname{deg}^{+}(v)\).
There are some specific graphs that are used often enough that it's worth giving them names.
A complete graph on \(n\) vertices is an \(n\) vertex graph with every possible edge.
That is, every vertex is adjacent to every other.
These are called \(K_n\).
Here are \(K_3\), \(K_4\), \(K_6\), \(K_8\):
\(K_n\) would represent the relation \(\{(a,b)\mid a\ne b\}\).
The graph that models an equivalence relation is a collection of complete graphs (plus loops on each vertex): one for each equivalence class.
A cycle on \(n\) vertices \(v_1,v_2,\ldots,v_n\) is the graph with edges \((v_1,v_2),(v_2,v_3),\ldots,(v_{n-1},v_n),(v_n,v_1)\).
They are called \(C_n\).
These are \(C_3\), and \(C_6\).
We can define an n cube (or n-dimensional hypercube), \(Q_n\) as follows…
The vertices will be every possible \(n\) bit value.
There will be an edge between two vertices when they differ by exactly one bit.
So, 1101 will be connected to 1100, but not 1000 or 1101.
These are \(Q_1\), \(Q_2\), \(Q_3\), and \(Q_4\):
We can also define cubes recursively. \(Q_0\) is a single node with no edges.
To create \(Q_{n+1}\), we make two copies of \(Q_{n}\) and join their corresponding edges.
Cubes have some nice properties.
There are \(2^n\) nodes.
They have relatively few edges: each vertex has degree \(n\).
There is a path between any two nodes with at most \(n\) steps. It's easy to figure out what that path is.
That's nice for a situation like connected processors: they can communicate effectively without requiring too much communications overhead.
Bipartite Graphs
A bipartite graph is a graph where the vertices can be partitioned into two sets where there are no edges within a partition.
For example in the graph, we can take \(\{a,b,c\},\{d,e,f\}\) as a partition of the vertices:
There are no edges between nodes in \(\{a,b,c\}\) or \(\{d,e,f\}\) so it is bipartite.
We will usually draw bipartite graphs like that: with the partitions on the left/right and all edges sort-of-horizontal between the two.
… or partitions on the top/bottom and the edges mostly-vertical.
Of course, we don't have to draw the graph like that for it to be bipartite. This is the same graph drawn two different ways, and it's still bipartite.
So depending on how it's drawn, it might not be obvious whether or not a graph is bipartite.
Are the cycles \(C_n\) bipartite? The cubes \(Q_n\)?
At least we can answer for the complete graphs \(K_n\). Only \(K_2\) is. The rest have too many edges.
If we can find a way to partition the vertices (into two partitions) so that there are no edges within the partitions, then it's bipartite, by definition.
One way to do that is to colour the vertices with two colours so no identically-coloured vertices share an edge:
A complete bipartite graph \(K_{m,n}\) is the bipartite graph with \(m\) and \(n\) vertices in the partitions with all of the allowed edges.
For example, here are \(K_{2,3}\) and \(K_{3,5}\):
Remember that we don't have to draw them that way. This is also \(K_{3,5}\):
If we draw the graph for a relation from one set to a different set, it would have been a bipartite digraph.
… assuming the two sets are disjoint.
For example, a relation from letters to words, where a letter is related to a word if it is in the word.
If we have a bipartite digraph, we'll also insist that all of the edges are in the same direction: from one partition to the other.
Basic Graph Operations
If we have some graphs, there are some fairly obvious operations we can do on them.
Given a graph \(G=(V,E)\), a subgraph of \(G\) is a graph \((V_1,E_1)\) where \(V_1\subseteq V\) and \(E_1\subseteq E\).
For example, for this graph,
Here are two subgraphs:
The union of two graphs \(G_1=(V_1,E_1)\) and \(G_2=(V_2,E_2)\) is \(G_1\cup G_2=(V_1\cup V_2,E_1\cup E_2)\).
For example, here is the union of the two graphs above:
This is also a subgraph of the original above.
Theorem: A graph is bipartite if and only if it does not contain an odd-length cycle as a subgraph.
Proof:
[Only if: odd cycle implies not bipartite.]
Suppose we have a graph that contains an odd cycle. Let \(v_1,v_2,\ldots,v_n\) be the vertices in the cycle, with \(n\) odd. We can try to form two partitions \(A,B\) of the vertices.
Without loss of generality, we put \(v_1\) in \(A\). Then \(v_2\) must be in \(B\) since \(v_1\) and \(v_2\) are adjacent. Similarly, \(v_3\) must be in \(A\). We will have all odd-numbered vertices in \(A\) and even-numbered in \(B\).
Then \(v_n\) is in \(A\). Since there is an edge from \(v_1\) to \(v_n\), we cannot construct a partition to satisfy the definition of a bipartite graph.
[If: no odd cycles implies bipartite.]
We can form a partition \(A,B\) as follows. Start with any vertex \(a\) and put it in partition \(A\). For each other vertex \(v\), look at the length \(n\) of the shortest path from \(a\) to \(v\) in the graph. If \(n\) is even, put \(v\) in \(B\); if it is odd, put it in \(A\).
Suppose we have two vertices \(v_1\) and \(v_2\) that are adjacent but in the same partition. Then the path from \(v_2\) to \(a\), plus the path from \(a\) to \(v_1\), plus the edge \((v_1,v_2)\) forms an odd-length cycle, and we have a contradiction.∎
[We haven't actually defined “shortest path in a graph” for the above proof, but it means exactly what you might expect.]
This theorem gives us something we might be able to calculate to test for bipartite-ness.
If we can come up with some algorithm to find odd cycles, we can use it to check if a graph is bipartite.
Representing Graphs
There are several ways of representing graphs.
… in a way we can write algorithms on them.
The “right” way is going to depend on the graph and the algorithm we want to use.
Maybe the most obvious: an adjacency list.
For each vertex, keep a list of vertices that are adjacent to it.
For example, if we have this graph:
The adjacency list is just:
\(a\):
\(\{b,c,e\}\)
\(b\):
\(\{a,b\}\)
\(c\):
\(\{a,d,e\}\)
\(d\):
\(\{c,e\}\)
\(e\):
\(\{a,c,d\}\)
For a directed graph, we can obviously just list the outgoing vertices.
… or incoming vertices if that's more useful to the application at hand.
The storage required for the adjacency list is going to be \(\Theta(|V|+|E|)\).
We can also represent a graph as an adjacency matrix, in exactly the way we represented a relation: 1 for a connection and 0 otherwise.
For the graph above,
\[\left[\begin{matrix}0&1&1&0&1 \\ 1&1&0&0&0 \\ 1&0&0&1&1 \\ 0&0&1&0&1 \\ 1&0&1&1&0 \\ \end{matrix}\right]\]
For an undirected graph, the matrix will always be symmetric.
For a (non-symmetric) directed graph, it won't be.
\[\left[\begin{matrix}0&1&0&0 \\ 0&0&1&0 \\ 0&0&0&1 \\ 1&0&0&0 \\ \end{matrix}\right]\]
We could allow numbers other than 0 and 1 to represent a multigraph.
The storage required for the adjacency matrix is going to be \(\Theta(|V|^2)\).
Graph Isomorphism
When looking at bipartite graphs, I drew these and pointed out that they were all the same graph:
Even if we re-label the verties, it's still basically the same graph, but if we re-label and move things around, it's going to be really hard to tell.
The concept of graph isomorphism captures this similarity.
Given two graphs, \(G_1=(V_1,E_1)\) and \(G_2=(V_2,E_2)\), we will say that they are isomorphic if there is a bijection \(f\) from \(V_1\) to \(V_2\) where \((a,b)\in E_1\) iff \((f(a),f(b))\in E_2\).
Then \(f\) is called the isomorphism.
An isomorphism that maps the first to the last graph above is \(f(a)=q\), \(f(b)=r\), \(f(c)=s\), \(f(d)=t\), \(f(e)=u\), \(f(f)=v\).
For example, if we are looking at graphs for molecules, then there's something interesting about two molecules being isomorphic.
Apparently, databases of chemicals are arranged by isomorphism of the molecule.
Aside: isomorphism is an equivalence relation on graphs.
Reflexive: identity function.
Symmetric: inverse function.
Transitive: function composition.
Deciding whether or not two graphs are isomorphic is sometimes easy.
Obviously, if \(|V_1|\ne|V_2|\) or \(|E_1|\ne|E_2|\), then they aren't isomorphic.
If the vertices have different degrees, then they can't be isomorphic. (e.g. if \(G_1\) has two nodes with degree 4, but \(G_2\) has three, they won't be isomorphic.)
But these pairs of graphs pass all of those tests, but are not isomorphic:
We could come up with other easy-to-check properties that would be preserved by an isomorphism.
e.g. “contains a 4-cycle” or “has adjacent vertices of degree \(m\) and \(n\)”.
These are graph invariants.
But we could always come up with some example like the above which has the right properties but is not isomorphic (or is as hard to compute as isomorphism).
Properties like “has a node labelled \(a\)” are not invariants.
Deciding whether or not two graphs are isomorphic is hard to do algorithmically.
Actually, coming up with an algorithm is easy:
procedure find_isomorphism(V1, E1, V2, E2)
if |V1| ≠ |V2| or |E1| ≠ |E2|: return false
for every possible bijection from V1 to V2
check to see if each edge in E1 maps onto an edge in E2 under that function
if it does: return the function
return false
But that's not exactly a fast algorithm: there are \(|V|!\) possible functions and \(|E|\) work to check each one.
So the running time is \(\Theta(|E|\cdot|V|!)\) worst case. That's pretty bad.
The best known algorithm for graph isomorphism is \(O(2^{\sqrt{n\log n}})\).
[I think \(n\) there is \(|V|+|E|\), but can't find a source to confirm.]
That's much better: \(O(2^{\sqrt{n\log n}})\) is smaller than \(O(2^n)\), but the \(O(n!)\) for my solution is bigger.
But it's still exponential.
As with other “hard” problems, having a bad worst case might not be a complete disaster.
Maybe we (or somebody else) could come up with a decent algorithm for certain kinds of graphs.
e.g. graphs with no loops. That sounds easier.
Maybe we could come up with an algorithm that has a good-enough average case for the kinds of graphs we actually care about.
… even if the worst case is really bad for graphs we don't use very often in a particular application.